I am wondering that if I keep my academic works in GitHub, would be a problem related plagiarism?
Or, should I use Codeberg or GitLab etc?
Has Typst.app a specific implementation to keep data safe?
I am wondering that if I keep my academic works in GitHub, would be a problem related plagiarism?
Or, should I use Codeberg or GitLab etc?
Has Typst.app a specific implementation to keep data safe?
Hello @ertugruluyar,
Like any security question, you must first define your threat model. What are you trying to defend against? If you are worried about plagiarism of your work during its conception, before you publish, then yes having a public repository on GitHub is probably a bad idea. A rival actor could “take over” and publish faster based on your work.
For the webapp, as long as you don’t share your project publicly, I don’t see any reason that your work would be disclosed without your agreement. Relying on a third-party means you trust them to keep your data safe, if you read the terms & conditions, you will see
If you do not trust Typst GmbH to keep your data secure, then you can ask for an on-premises instance, see Typst: Pricing. However, that means you are in charge of security.
The same reasoning applies to other forges like Codeberg, GitLab, or other services like Overleaf.
Thank you @quachpas. The threats are the plagiarism softwares. Sorry, I forget to add the how I worried. I mean, Microsoft using the data from GitHub to training their AI, so if Turnitin etc. index those data then when I check the plagiarism via this softwares, could be an plagiarism issue. Right?
So, even if keep my repository private, would be a problem?
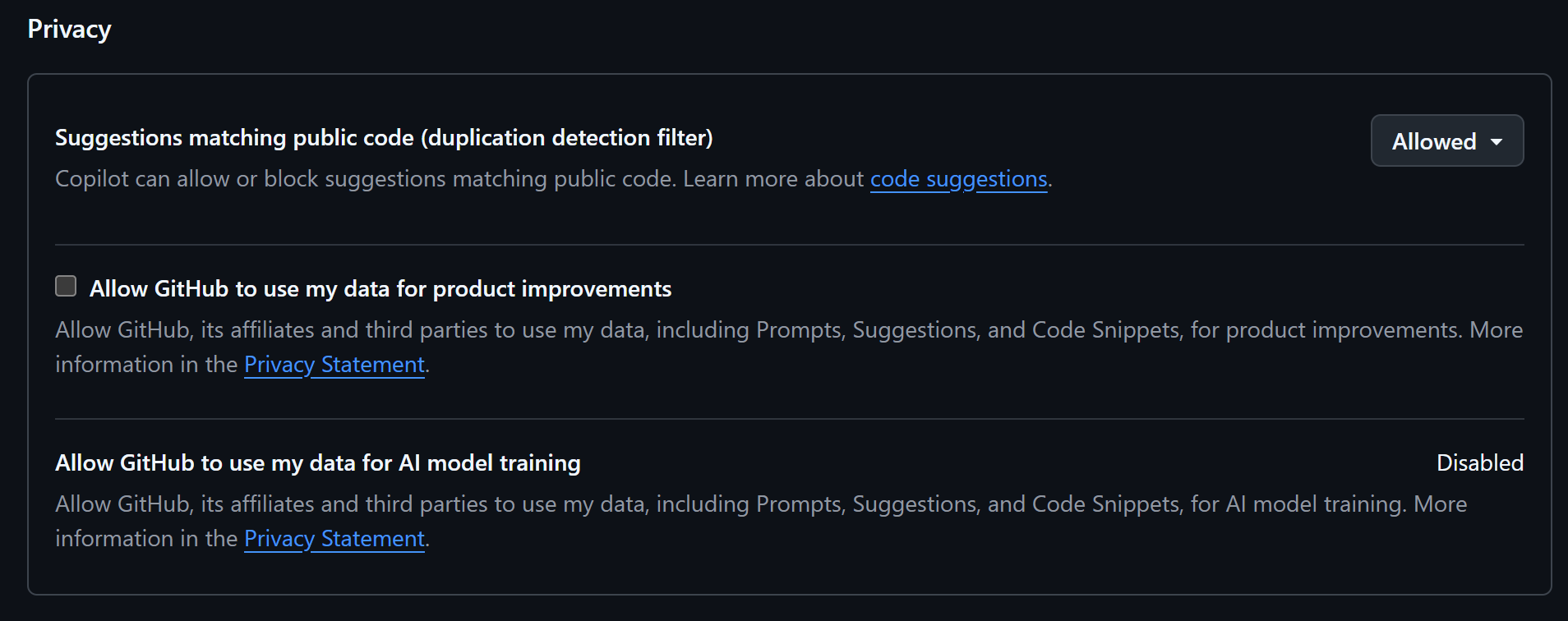
See Managing Copilot policies as an individual subscriber - GitHub Docs. By default GitHub should not use your data to train their AI.
That does not prevent third-parties from adding your code to their dataset if it is publicly accessible.
If your work is detected as a plausible plagiarism of your own work, i.e., self-plagiarism, (that happens quite often with master’s thesis and subsequent publications), then it is quite trivial to resolve the plagiarism case. Be aware that some publishing venues explicitly refuse to publish work that is too similar to already published works, e.g., publishing a paper based on your master’s thesis. See Self-Plagiarism or Appropriate Textual Re-use? | Journal of Academic Ethics for a discussion on this topic.
@quachpas So, technically, if I keep my repository private, couldn’t be a problem then, right?
I disabled the settings in my GitHub account:
Realistically, it shouldn’t be a problem with a public repository, but especially with the private one.
As to data collection, it was stated many times throughout the Internet that github.com and gitlab.com are for-profit companies (their websites), so it’s for you to decide if you trust them or not. I’ve seen a few claims that GitHub does train on public data, otherwise how can they train the model. Not sure about private repos. It’s run under Microsoft. I don’t trust that company, which is one of the reasons that I don’t use any of their stuff, except, well, the GitHub, because this is the only place where I can create an issue or a pull request to Typst or some other FOSS projects that I use.
So if secret data usage is an issue, my advice is to use a privacy focused cloud storage provider like MEGA or Git hosting service like Codeberg. Although, you still have to trust these companies.
You can just have backups on other storage devices or make your own Git service with Gitea, Forgejo, GitLab, etc.
Thank you so much for the suggestions, I couldn’t trust Microsoft %100 either. I will consider using Codeberg.