I am currently doing an article with a lot of Sanskrit and Pali words in the text. Most of these words have diacritics. I went through the accent function in Typst documentation but could not understand how to type one or two accented characters once or twice in every sentence. As you all know, Latex had language pack support. Help much appreciated. thanks.
1 Like
I think this is the same thing as this thread (Typst) about umlaut, where I think the TL;DR is that this is an input (OS) problem, not a Typst problem. Set up your OS and keyboard so that you can type whatever you need to type in the language that you are typing, and it’s done. Typst support UTF-8 encoding of files, therefore you can insert any character from any language/script, which also in turn will make it easier to read it and review it.
I don’t have to deal with accents, thankfully (at least for the time being), but as a Japanese enjoyer/learner, I wouldn’t expect Typst to provide a way to insert all of the thousands of characters that are used in Japanese only by using the US English OS layout. I can write a wrapper hiragana(), that will convert "ka" to か, but this would be insane to read even a shortened version like:
#hi[hi]#hi[ra]#hi[ga]#hi[na]
instead of just using an IME that can be used in any practical OS, and simply write
ひらがな
And this is only for hiragana. You would also have to have a different wrapper for katakana, but when you need to deal with kanji — good luck. As “しめる” with kanji will have one reading, but you would somehow need to choose through Typst API between something like 占める (occupy), 閉める (close), 締める (fasten).
So accents are basically like that, but you can type most of the things using the “standard” QWERTY keyboard layout for English. So facilitating one and not the other seems like a weird choice. A long time ago, I tried some Neovim plugins to basically have IME for Japanese without using OS’s IME. But that is a plugin, not a built-in solution, because editors also don’t have to facilitate this, they are for editing, not inputting. Just use a better layout or a compose key.
Anyway, you can open an issue requesting a feature, if you really want to. Use arbitrary characters as accents · Issue #422 · typst/typst · GitHub might be related.
4 Likes
There is some discussion about this - a feature request - over in the issue text.accent function counterpart to math.accent · Issue #833 · typst/typst · GitHub
If we use one of the workarounds there it could look like this:
// combining accents
#let grave = "\u{300}"
#let acute = "\u{301}"
e#grave;e#acute; are the same as èé.
// combining accents
#let svarita = "\u{0951}"
अ#svarita;प#svarita;
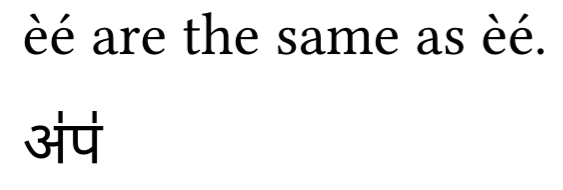
But then you have to excuse that I just grabbed the first info I could find from Vedic accent - Wikipedia and guessed that this could be an example of an accent you want to use - the example is probably nonsense! The same method/syntax works for any unicode codepoint that’s a combining accent.
If the syntax of the workaround or eventual solution should be e#acute; or #acute("e") or #acute[e], or anything else, I don’t know, they are all hard to read in the source text…
I am on Linux Mint, US international keyboard. I dont think it is as easy as you suggest. In case I am not getting your point, could you plese elaborate? Thanks.
Considering that those 2 languages are basically not used(?), for them specifically, you will probably have hard time finding an IME. Although there are few options for Indic languages at https://wiki.archlinux.org/title/Input_method#List_of_available_input_method_editors.
According to https://en.wikipedia.org/wiki/Pali#Alphabet_with_diacritics, you can use the Roman script. In that case, you would probably use a compose key, with a standard OS input source. If a compose key is not as fast/comfortable, then you would have to either modify your keyboard layout, or use some key mappings, or projects like GitHub - jtroo/kanata: Improve keyboard comfort and usability with advanced customization, that allows to have different configs/layers for a given keyboard. Which is a host-level software. For programmable keyboards like Glove80, you can use (ZMK) firmware-level keyboard layouts, config, layers, etc.
So there are many options overall.
Bluss, thanks. I am not writing foreign words in English. Sanskrit and Pali words are shown in English spelling with diacritics. example: yathā-bhūta-ñāna. Workarounds using extended syntax can be tiresome. I would like to have simple keyboard inputs/shortcuts based on language pack support as in Latex. Beginning to like Typst, but lack of this feature can be quite a let down.
If you are transliterating words, the US International keyboard should support adding accents by default. If that gets too tiresome, Keyman from SIL should have a keyboard layout available with the accents you need in a couple key-presses. Which romanisation standard are you using? I found this keyboard which uses ISO 15919 except e and o, which use IAST. Since you use Mint, the Ubuntu PPA for Keyman should work.
1 Like
S_Save, thanks for discovering slp_1 Roman keyboard for me. But I can’t be switching back and forth between keyboards while typing an essay, right? That would be a royal pain in you-know-where if you are composing an essay of several pages. Anyway, it was very kind of you to take time up to look up and trying to help me. Cheers.
Can you quickly describe what those shortcuts in latex are? Maybe they’re simple to duplicate.
\'a for á
\`a for à
1 Like
I agree that Latex’s way of handling accents is way easier than
e#grave;e#acute; are the same as èé.
I failed to find a way to type accented characters easily.
I created a file called accents.typ with the following contents:
#show "\\'E": [É]
#show "\\'I": [Í]
Then, in main.typ i wrote :
#include "accents.typ"
but it did not work.
I then used chatgpt to change accents.typ to :
#let accent-map = (
// Acute
"\\'A": [Á], "\\'E": [É], "\\'I": [Í], "\\'O": [Ó], "\\'U": [Ú], "\\'Y": [Ý],
"\\'a": [á], "\\'e": [é], "\\'i": [í], "\\'o": [ó], "\\'u": [ú], "\\'y": [ý],
// Grave
"\\`A": [À], "\\`E": [È], "\\`I": [Ì], "\\`O": [Ò], "\\`U": [Ù],
"\\`a": [à], "\\`e": [è], "\\`i": [ì], "\\`o": [ò], "\\`u": [ù],
// Circumflex
"\\^A": [Â], "\\^E": [Ê], "\\^I": [Î], "\\^O": [Ô], "\\^U": [Û],
"\\^a": [â], "\\^e": [ê], "\\^i": [î], "\\^o": [ô], "\\^u": [û],
// Tilde
"\\~A": [Ã], "\\~N": [Ñ], "\\~O": [Õ],
"\\~a": [ã], "\\~n": [ñ], "\\~o": [õ],
// Umlaut / diaeresis
"\\\'A": [Ä], "\\\'E": [Ë], "\\\'I": [Ï], "\\\'O": [Ö], "\\\'U": [Ü], "\\\'Y": [Ÿ],
"\\\'a": [ä], "\\\'e": [ë], "\\\'i": [ï], "\\\'o": [ö], "\\\'u": [ü], "\\\'y": [ÿ],
// Cedilla
"\\cC": [Ç], "\\cc": [ç],
// Ligatures
"\\ae": [æ], "\\AE": [Æ], "\\oe": [œ], "\\OE": [Œ],
// Other Latin-1 specials
"\\ss": [ß], "\\DH": [Ð], "\\dh": [ð], "\\TH": [Þ], "\\th": [þ],
"\\O": [Ø], "\\o": [ø],
)
and i applied those modifications to main.typ :
#import "accents.typ": accent-map
#show document: it => {
// Build up a body in which each mapping has been turned into a show rule.
let body = it
for (k, v) in accent-map {
body = {
// 'k' is the selector (e.g. "\\'e"), 'v' is content (e.g. [é])
show k: v
body
}
}
it
}
but it still did not work.
I then added the following to accents.typ :
#let apply-accents() = {
for (k, v) in accent-map {
show k: v
}
}
then i applied those modifications to main.typ :
#import "accents.typ": apply-accents
#apply-accents()
But again it did not work.
It is very important for me that latex competitor markup language supports the following syntax (or at least an easy equivalent)
`\'a` for á
`\`a` for à
Let’s say you have the following style or “template”:
and you want to define it in another file. Then we need to make a template function. It’s described step by step in the docs here but the example is a bit big. We can simplify it.
In accents.typ we define:
#let apply-accents(doc) = {
show "'E": [É]
show "'I": [Í]
doc
}
In our main document document.typ we use the style function like this:
#import "accents.typ": apply-accents
#show: apply-accents
'E
Now it will work. Note the doc argument. Typst literally needs you to pass the whole document so that the show rule can transform it, and return the result.
1 Like
it works, thanks.
Although i realised that writing in typst the following :
sed 's/\\'E/REPLACEMENT/g'
Would automatically replace the \\'E by É. the rendered pdf text would look like :
sed 's/É/REPLACEMENT/g'
which is unforgiving behavior i think.
Therefore, I would like \'E shortcuts to be implemented in typst.
What went wrong here is that you returned it in the end instead of body. it is the unmodified original content.
1 Like
Thanks, but the below code does not work either.
#import "accents.typ": accent-map
#show document: it => {
// Build up a body in which each mapping has been turned into a show rule.
let body = it
for (k, v) in accent-map {
body = {
// 'k' is the selector (e.g. "\\'e"), 'v' is content (e.g. [é])
show k: v
body
}
}
body
}
either way, bluss’s answer works well, but I still stand by my previous remark about undesirable side effects such as :
sed 's/\\'E/REPLACEMENT/g'
being replaced by
sed 's/É/REPLACEMENT/g'
I think you want #show: it => { here, then it will work.
2 Likes
Based on your comments on the issue tracker, I understand one thing more now, and I will try to clarify:
#show "\\'E": [É]
You are trying to make a replace rule that matches slash apostrophe E as a sequence. I didn’t really understand this before (I thought the slash was escaping for the single quote). I think the rule is correct, it serves this purpose.
However, note that if you type \ in a typst document you get a linebreak. So if you want a literal slash you have to type \\. So the document markup that matches your replace rule is this:
\\'E
and that might explain why you thought it doesn’t work. It does work, but only like this:
#show "\\'E": [É]
\\'E
I don’t think you can (or that you should, if you could) try to redirect the default linebreak syntax.
1 Like
Oh indeed.
I forgot to say that I’m grateful for the developers’ hard work for such a power latex competitor. It’s pretty nice to run python and output it to a pdf document. Almost like jupyter.