Hi all,
Over the past several months I’ve been building two packages to cover two broad subfields in linguistics, one of which is my own area of work (phonology). Both aim for the same thing: minimal, readable input syntax with no loss of typographic quality — and a comfortable landing spot for people migrating away from tikz-qtree, forest, tipa, and hand-built OT tableaux in LaTeX.
phonokit — phonological representations
IPA transcription (with familiar tipa-style input, so you’re not hunting for Unicode), prosodic structure (syllables, moras, feet, prosodic words, metrical grids), autosegmental diagrams with spreading and delinking, multi-tier representations, SPE feature matrices, feature geometry, sonority profiles, IPA vowel charts and consonant tables, chain shifts/mergers/splits, and a full set of constraint-based tools: OT tableaux, Harmonic Grammar, Noisy HG, and MaxEnt, plus Hasse diagrams. Tableaux add shaded cells automatically (if you so choose), and MaxEnt tableaux calculate probabilities automatically (plus, you can easily sort candidates by highest to lowest probability).
The code below will assume that the main foot in the word is right-aligned, but you can change that with foot: "L". All functions work similarly: you adjust parameters based on your needs.
#word("('po.Ra).('ma.pa)")
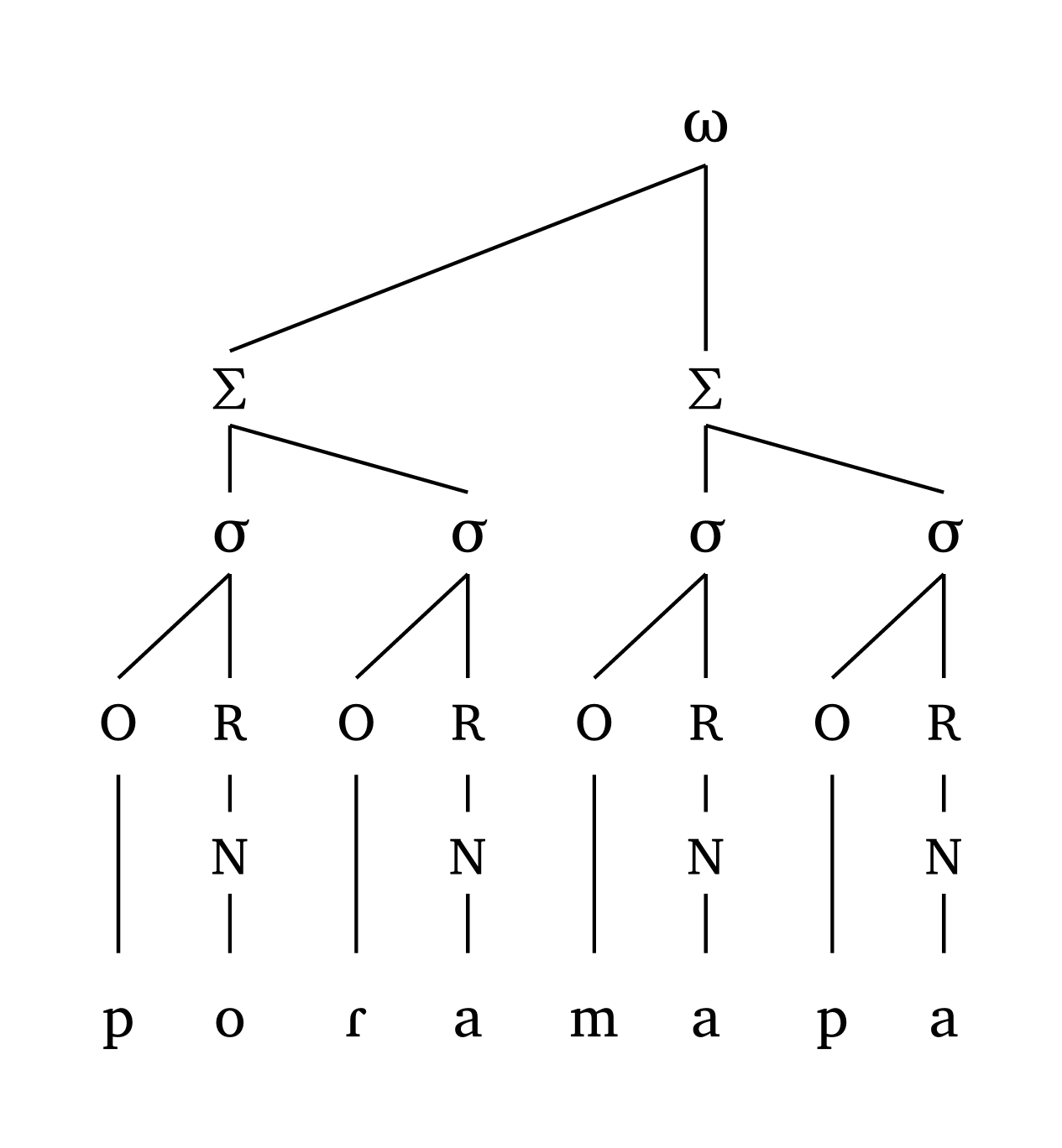
synkit — syntax & semantics
Phrase-structure trees from bracket notation where spacing is forgiving ([NP[Det][N]] parses the same as the spaced-out version). Labels and triangles are generated automatically, so you rarely create either by hand. On top of that: movement arrows (curved or rectangular, individually styleable), multidominance and long-distance dominance lines, cross-tree equivalence lines via #garden() (handy for bilingual comparisons), semantic annotation between a node and its branches, in-line movement with #move(), and numbered examples (#eg()) and interlinear glosses (#gloss()) that share a single numbering stream.
#tree(
"[ CP [ C' [ C Ø_{[+Q]}+T+Mangez ] [ TP [ DP vous ] [ T' [ T *t*_i ] [ VP [ *t*_DP ] [ V' [V *t*_i ] [DP des pommes] ] ] ] ] ] ]",
arrows: (
(from: "trace3", to: "T1"),
(from: "trace2", to: "DP1"),
(from: "trace1", to: "C1"),
),
curved: true,
)
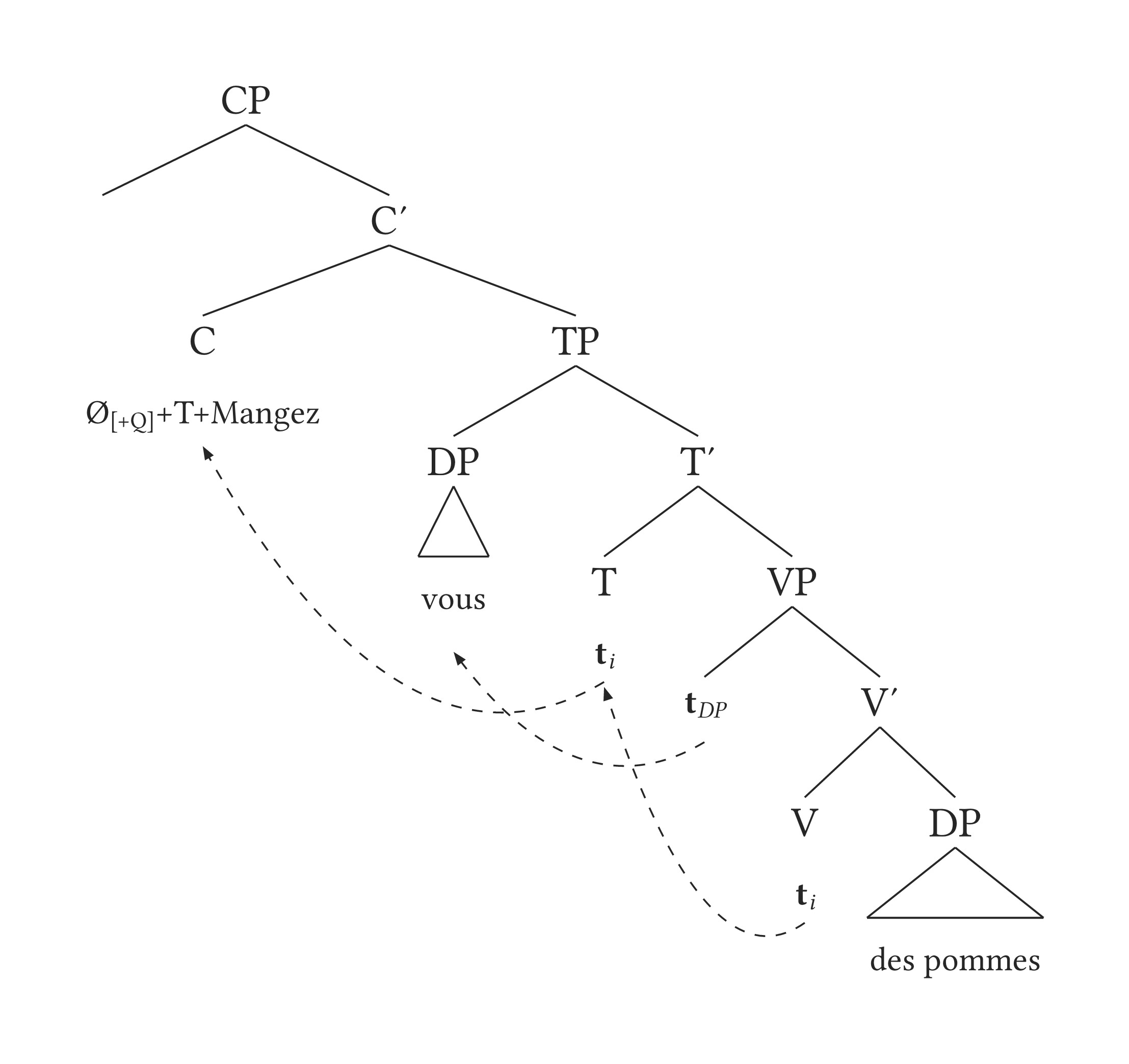
One crucial feature is that labels are automatically created for all nodes, and you can “turn on” the helper in the function (show-refs: true) to temporarily print all labels as you create your arrows, etc. The labels you see above (trace3, T1, etc.) are thus created by the function, not the user.
Both are MIT-licensed, archived on Zenodo with DOIs, and have comprehensive manuals with a wide range of examples:
- phonokit → phonokit – Guilherme D. Garcia
- synkit → synkit – Guilherme D. Garcia
They’re young (especially synkit), so feedback, edge cases, and feature requests are very welcome — I’d particularly like to hear from anyone doing syntax/semantics or constraint-based phonology about what’s missing for real-world papers.
Thanks for taking a look!