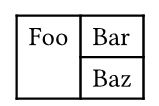
I have a very basic question today about the table element: why are we expected to give a single list of cells to represent a two-dimensional table, instead of passing a list of arrays, each representing one row?
For example, in the table guide, instead of
#table(
columns: 2,
[*Amount*], [*Ingredient*],
[360g], [Baking flour],
[250g], [Butter (room temp.)],
[150g], [Brown sugar],
[100g], [Cane sugar],
[100g], [70% cocoa chocolate],
[100g], [35-40% cocoa chocolate],
[2], [Eggs],
[Pinch], [Salt],
[Drizzle], [Vanilla extract],
)
I would naturally have expected something like:
#table(
([*Amount*], [*Ingredient*]),
([360g], [Baking flour]),
([250g], [Butter (room temp.)]),
([150g], [Brown sugar]),
([100g], [Cane sugar]),
([100g], [70% cocoa chocolate]),
([100g], [35-40% cocoa chocolate]),
([2], [Eggs]),
([Pinch], [Salt]),
([Drizzle], [Vanilla extract]),
)
(Or maybe #row(foo, bar) instead of just (foo, bar).)
This is closer to the way we think about tables, it looks (from an uninformed distance) easier to script with, and it would also be sensibly be more robust to the deletion or addition of a cell somewhere: instead of having the whole table reflow in a weird way if you add or delete a single cell, you could get a partial row or an error message.
(In general I would expect the table to be structured as a sequence of horizontal elements, which are not necessarily only rows, for example there could be horizontal lines or formatting data in the middle.)
The current unstructured choice looks odd at first glance, but it is not explained/justified/discussed at all in the table documentation. Is there a deep reason why we want table in this unstructured format? Is this just an error of youth that is too hard to change now? Do people recommend using another table library in practice?