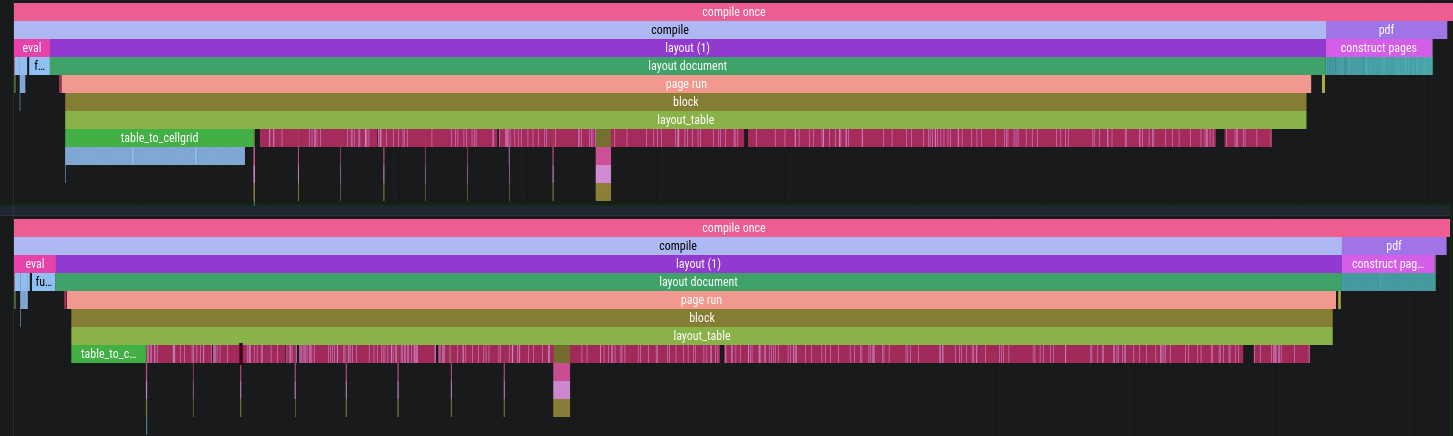
With the provided data I was able to replicate 10 s compilation time, but the amount of memory was used compared to reading from a CSV file… is a lot. I was getting around 2.6 GiB of RAM reported by btop. After changing to an external file it dropped significantly. With all optimizations it’s now at about 800 MiB and the time is slightly above 2 seconds.
#set page(margin: (x: 0.5cm, y: 0.5cm))
#set text(size: 8pt)
#let (header-row, ..data) = csv("data.csv")
#show table.cell.where(y: 0): strong
#table(
columns: header-row.len(),
inset: (x: 4pt, y: 3pt),
stroke: 0.4pt + luma(80),
table.header(..header-row.map(table.cell.with(fill: luma(245)))),
..data.map(row => (row.at(6) = link(row.at(6))) + row).flatten(),
)
Here, the fill callback function was removed because it was executed for each cell, which there are a lot of.
Moreover, with the added as is content I wasn’t able to get timings to save, because it was doing that for way too long.
In the end, I tried with the CSV file that has the same 10 rows repeated:
ID,Product Name,Description,Price,Category Name,Category Description,Image,Amount
1,Premium Coffee Beans,100% natural ingredients. No artificial preservatives.,5.60,Food,Quality Food from trusted brands,https://picsum.photos/seed/1/400/300,4043.20
2,Think and Grow Rich,Bestseller with excellent reader reviews. Available in paperback and hardcover.,4.19,Books,Quality Books from trusted brands,https://picsum.photos/seed/2/400/300,3569.88
3,Basic Product,Standard quality product with good value for money.,6.35,Health & Wellness,Quality Health & Wellness from trusted brands,https://picsum.photos/seed/3/400/300,425.45
4,Generic Item,Standard quality product with good value for money.,4.41,Home & Kitchen,Quality Home & Kitchen from trusted brands,https://picsum.photos/seed/4/400/300,3139.92
5,Generic Item,Standard quality product with good value for money.,7.14,Health & Wellness,Quality Health & Wellness from trusted brands,https://picsum.photos/seed/5/400/300,3805.62
6,Basic Product,Standard quality product with good value for money.,4.31,Automotive,Quality Automotive from trusted brands,https://picsum.photos/seed/6/400/300,4189.32
7,Basic Product,Standard quality product with good value for money.,2.20,Beauty & Personal Care,Quality Beauty & Personal Care from trusted brands,https://picsum.photos/seed/7/400/300,1216.60
8,Generic Item,Standard quality product with good value for money.,6.70,Sports & Fitness,Quality Sports & Fitness from trusted brands,https://picsum.photos/seed/8/400/300,6586.10
9,Generic Item,Standard quality product with good value for money.,5.94,Health & Wellness,Quality Health & Wellness from trusted brands,https://picsum.photos/seed/9/400/300,4098.60
10,Basic Product,Standard quality product with good value for money.,3.19,Automotive,Quality Automotive from trusted brands,https://picsum.photos/seed/10/400/300,3056.02
And came to the conclusion, that the memory usage and time spent compiling increases linearly for 10’000, 20’000, and 30’000 rows of data: 800/1600/2400 MiB, 2.2/4.5/6.8 s.
So, if we blindly divide 15 GiB by about 850 MiB and then multiply by compilation time for 10k rows, we get about 180k rows, 40 s and fully filled RAM. If swap is used, then you can handle bigger data.
For 1 million rows you would need only about 220 seconds, but…uhh, also about 80 GiB of RAM. I mean, with swap it’s probably achievable, but the compilation time with that will probably drastically increase, and the system can freeze.
P.S. Not sure if you need the links to the URLs, but I didn’t find that it affected the compilation time, though it might affect RAM usage and it most definitely increases file size: from 2.49 MiB to 16.80 MiB for 30k rows.